Linux命令学习之wc

文章目录
前言
在日常应用中,统计文件内容是一种常见的需求,可以通过 wc 命令来实现
Wc
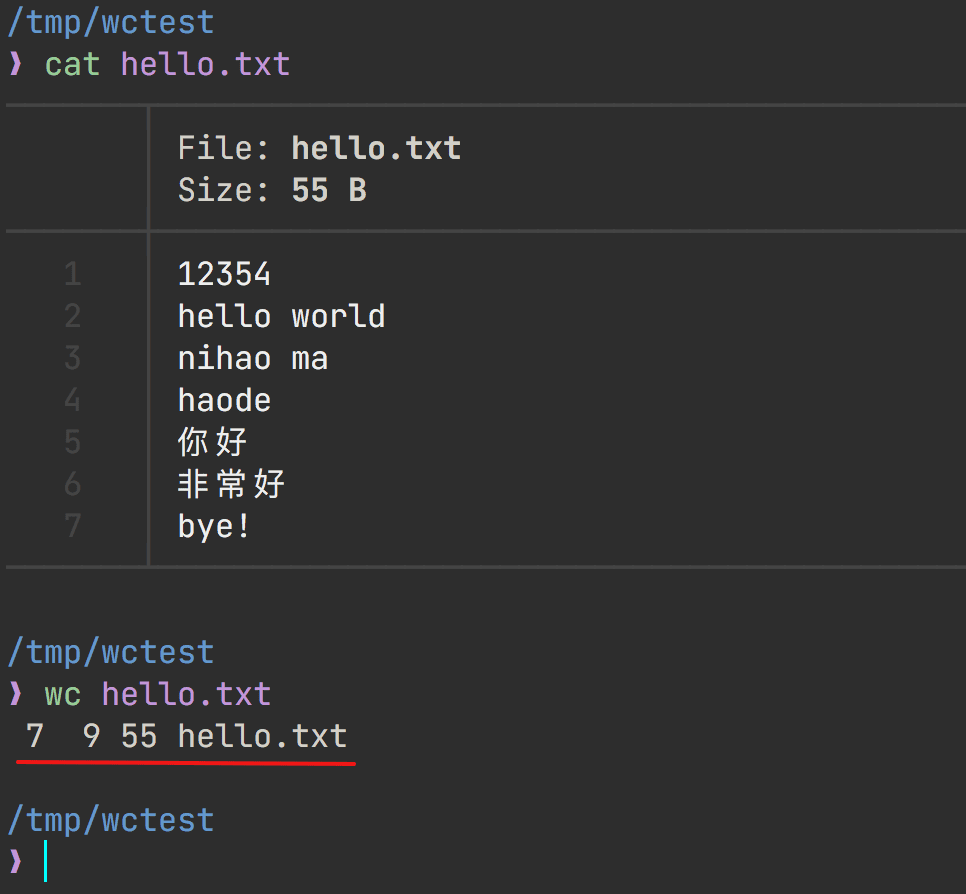
wc file
统计文件,显示行数、单词数、字节数,带文件名
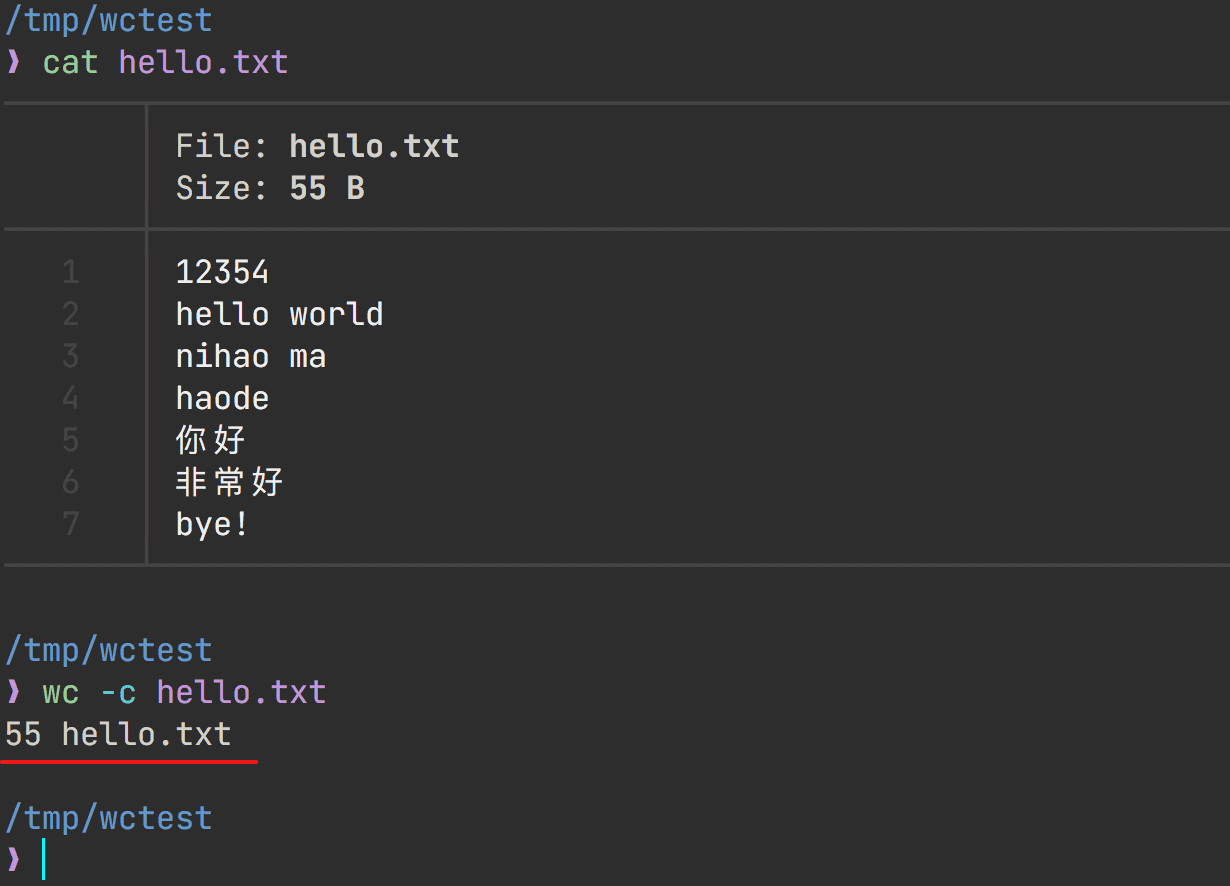
wc -c file
统计文件,只显示字节数
wc -w file
统计文件,只显示单词数

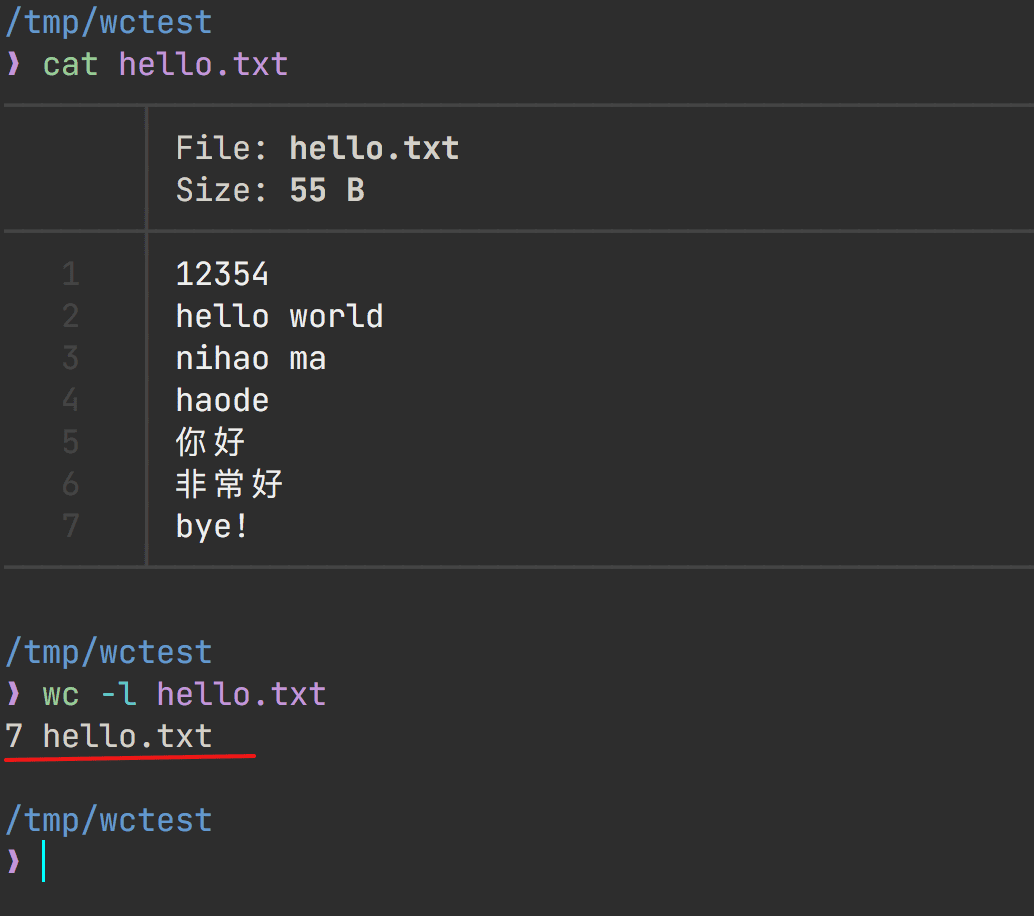
wc -l file
统计文件,只显示文件行数
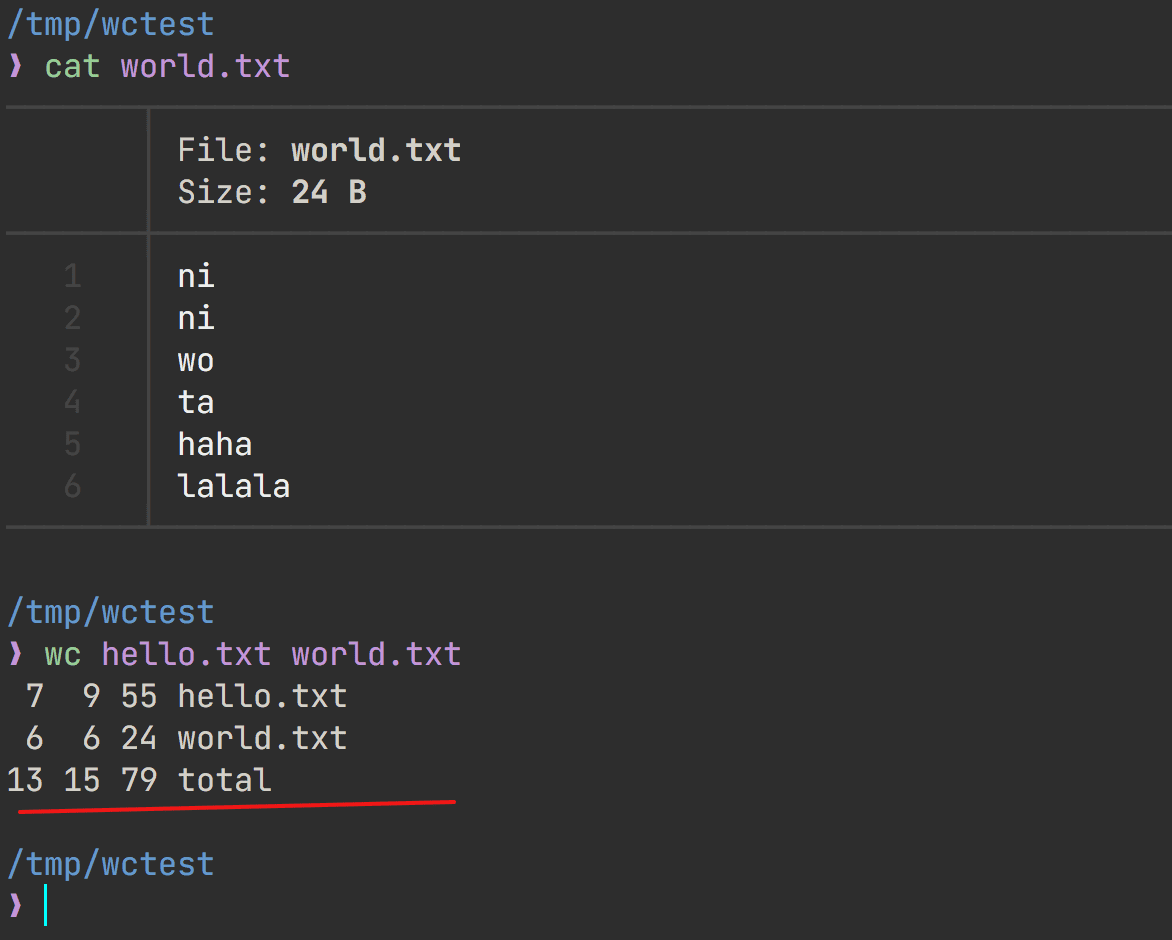
wc file1 file2
统计多个文件,显示汇总信息
wc < file
统计文件,显示行数、单词数、字节数,不带文件,便于shell脚本后续处理
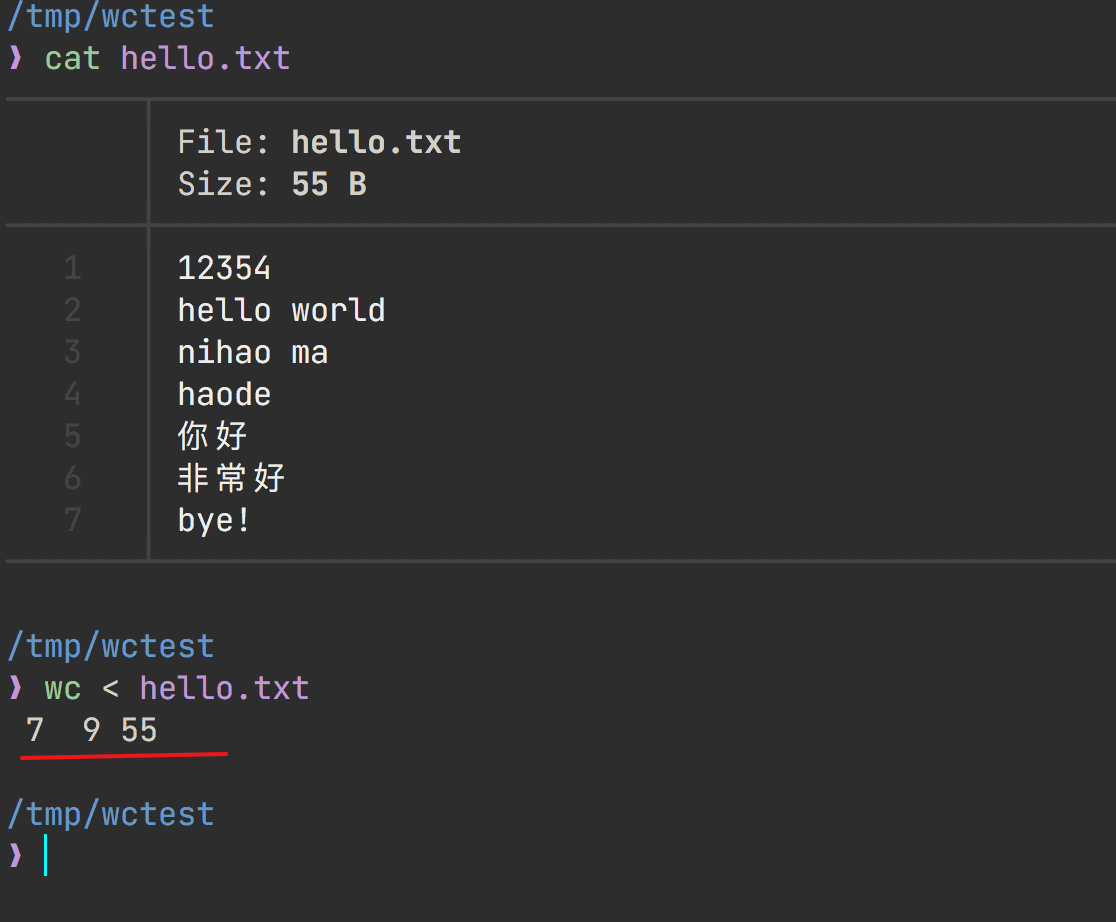
wc -L file
打印出文件行最长的节数
疑惑
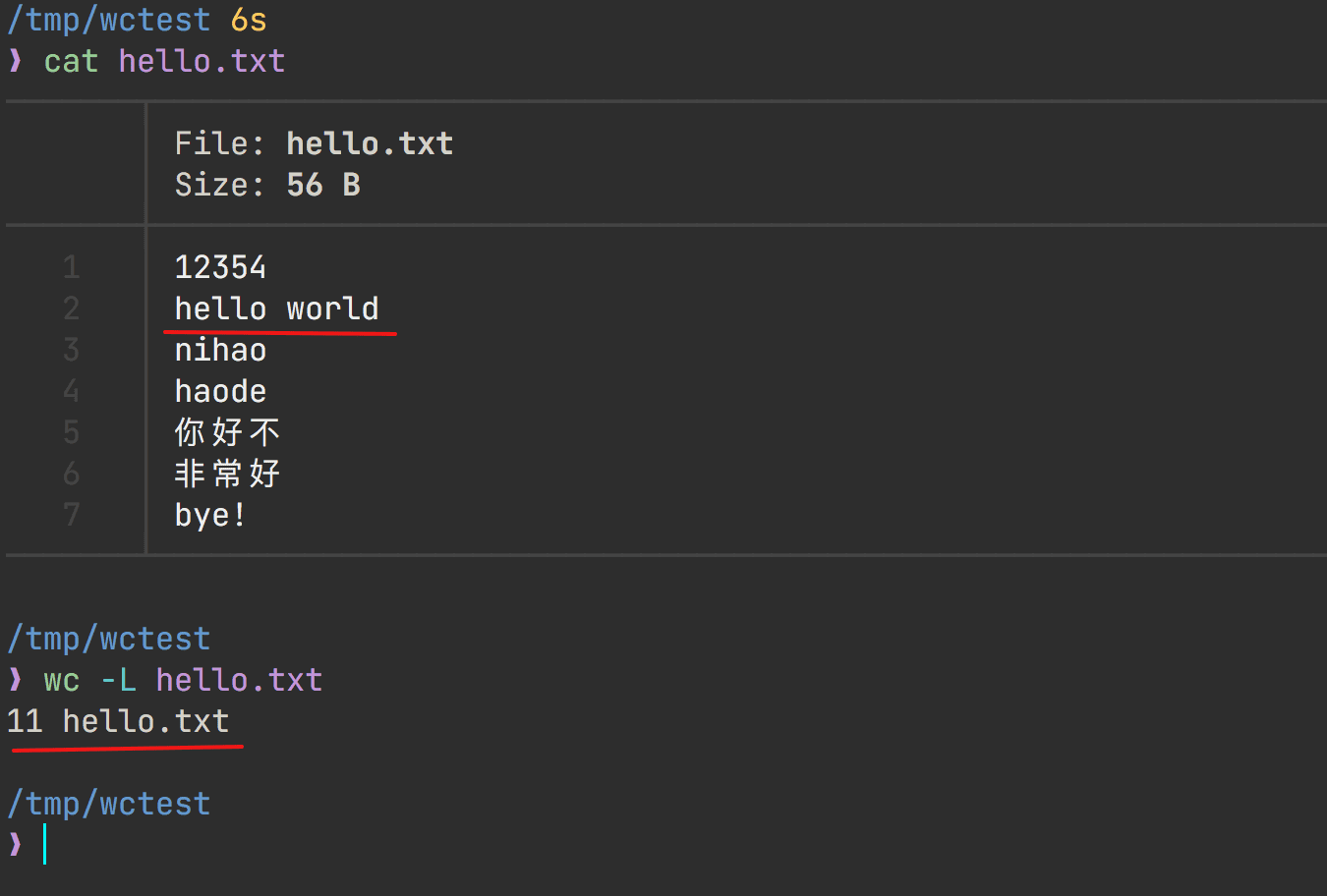
wc -c 与 wc -w 是如何统计的
在统计 hello.txt 时, wc -c 的结果为 55 , wc -m 的结果为 45 ,为什么统计的结果不一样?这个文本中包含了中文内容,猜测和这个有关
验证是否与中文有关
这个好办,建一个不带中文的文件,验证如下
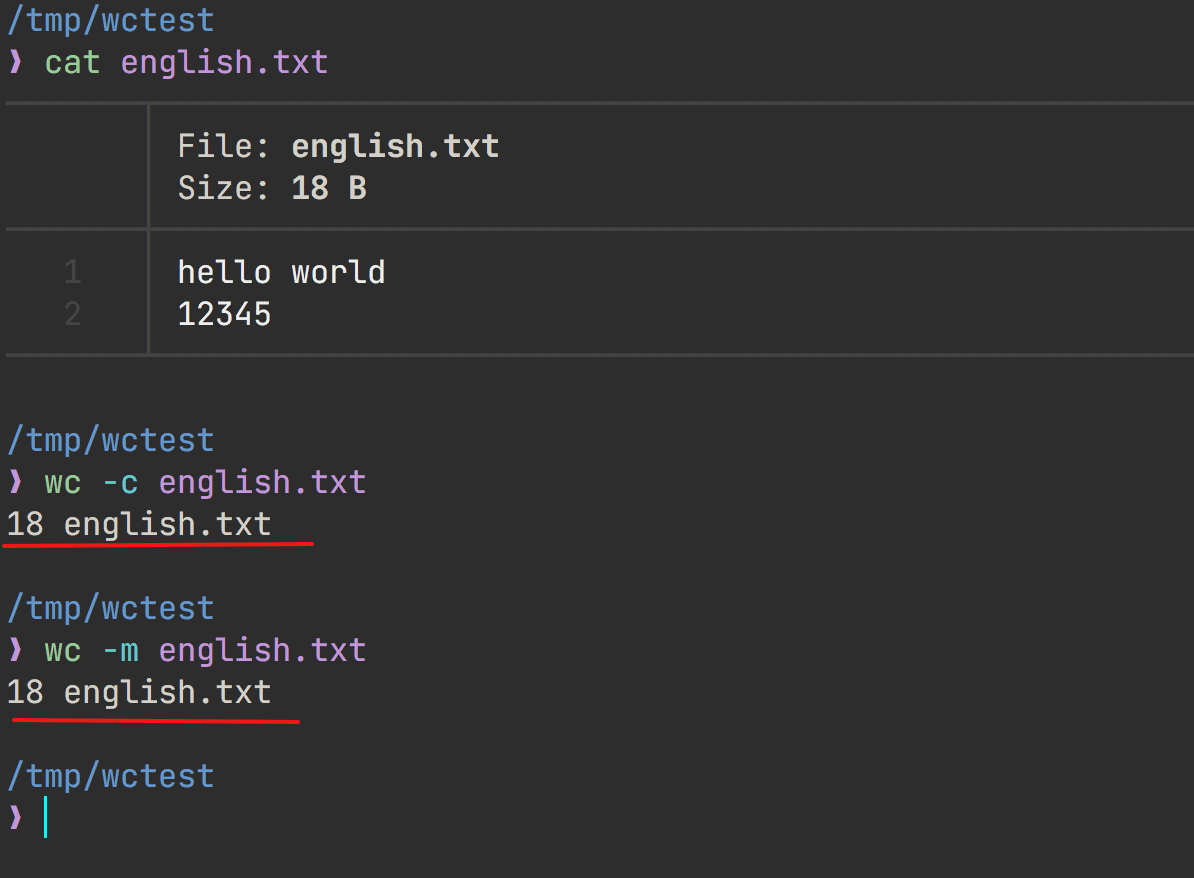
可以看到统计的结果是一样的
中文是如何统计的?
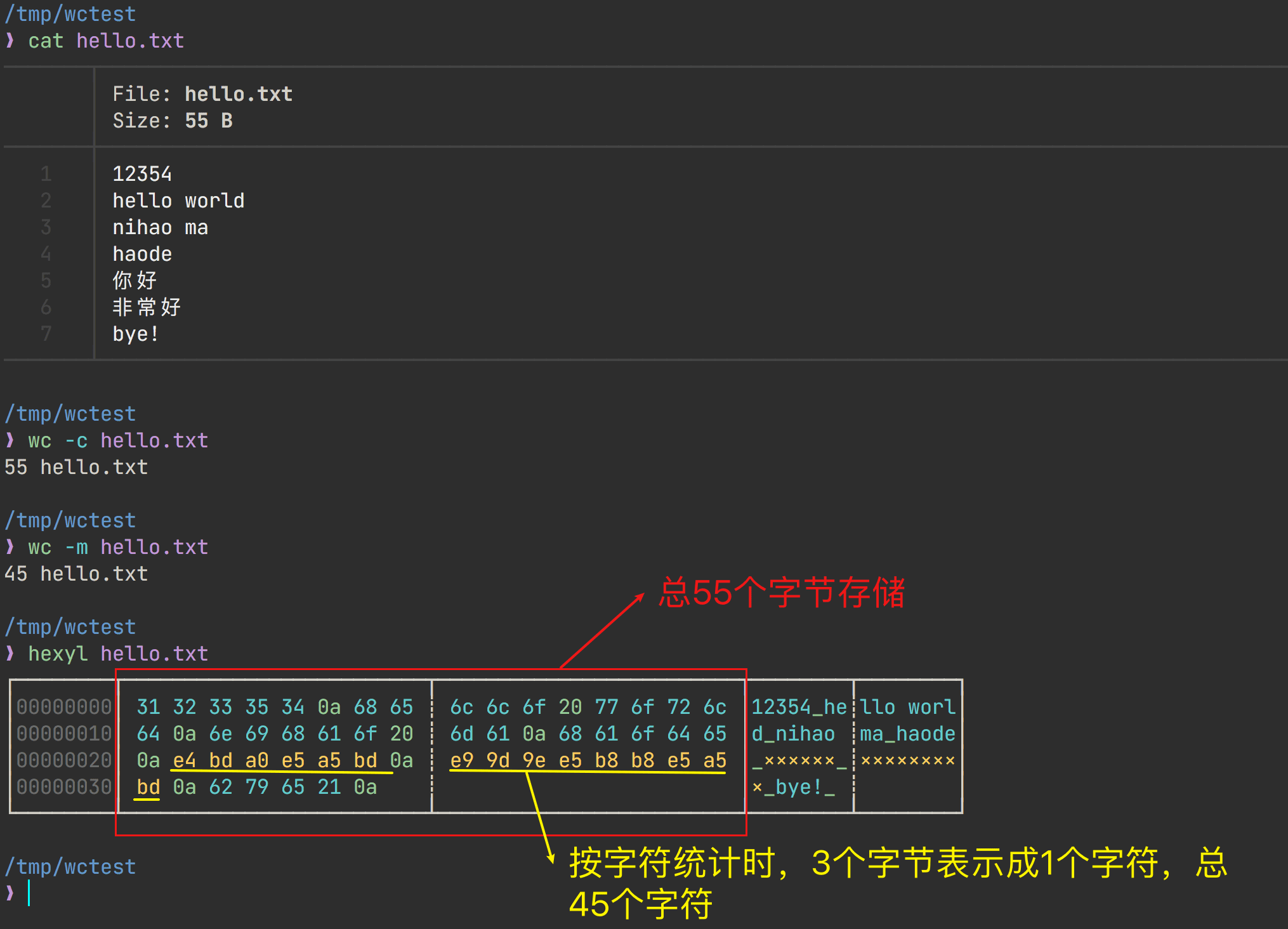
这个就涉及到编码的问题了,先用 hexyl 查看一下,字节的总数为55,但是在进行字符统计时,使用的unicode编码将3个字节计算为1个字符(例如 好 被编码成 E5 A5 BD ),这就对上了,哈哈!
编码是个大话题,后续好好学习一下
REF
wc (Unix) - Wikipedia
wc - How to display the number of lines, words and characters in separate lines? - Unix & Linux Stack Exchange
Captured On: [2023-03-02 Thu 16:28]