前言
最近在实践学习plantegg大佬的程序员案例,对IPC的实验进行一下记录,以备查验
术语说明
IPC
本文的主角,全名为 Instructions per cycle(clock), 表示每个时钟周期可执行的指令数,常用来做为评判处理器性能的指标
NOP
no operation, 在指令集中表示一个指令不改变所执行程序的 register,status flag,也就是不要进行上下文的切换,CPU的上下文切换是有时间开销的
实验代码下载
git clone https://github.com/plantegg/programmer_case
实验机器信息
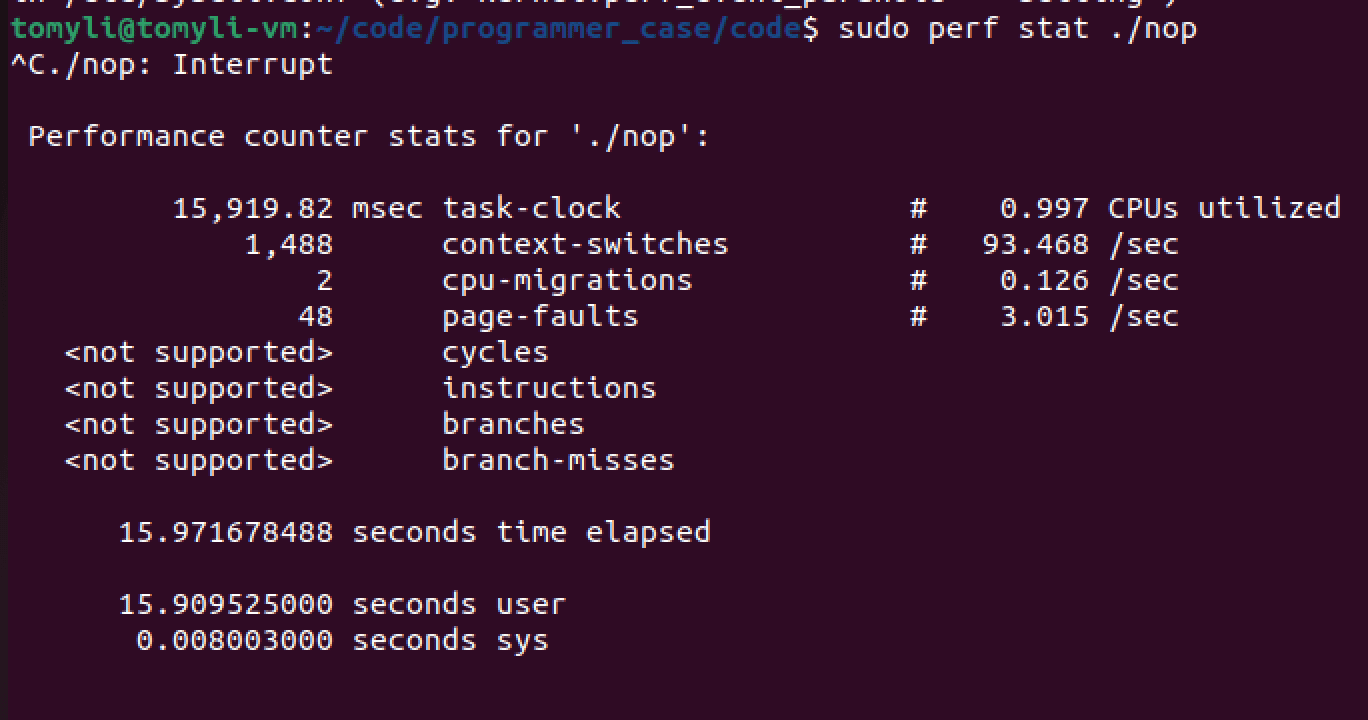
实验只可在物理机下进行
实验验证
测试nop指令
编译测试代码
gcc ./nop.c -o nop
执行测试
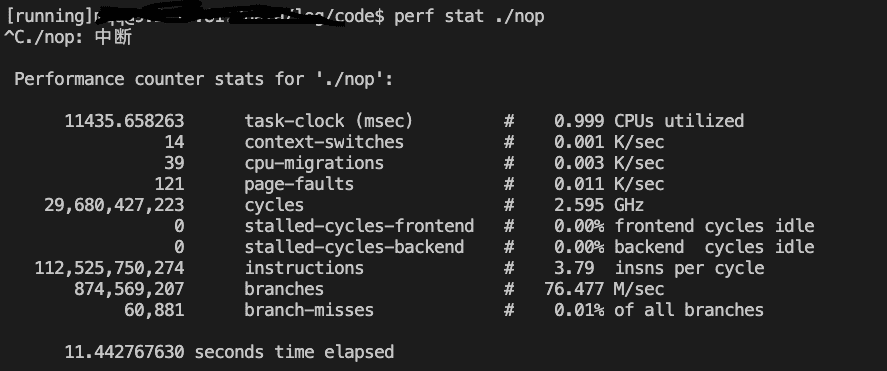
perf stat ./nop
现象
IPC跑到3.79
问题
- 我记得第一次执行IPC好像跑到了4(未改变代码),当时忘记截图了,后续测试的都到不了4了
- IPC与perf执行时间长短有关吗?
- 好像是无关的,保证cpu 100%后就可以停止进行查看
- IPC怎么接近4?
- 改代码增加nop指令的数量,加到将近700个,IPC达到3.97
测试pause指令
编译测试代码
gcc ./pause.c -o pause
执行测试
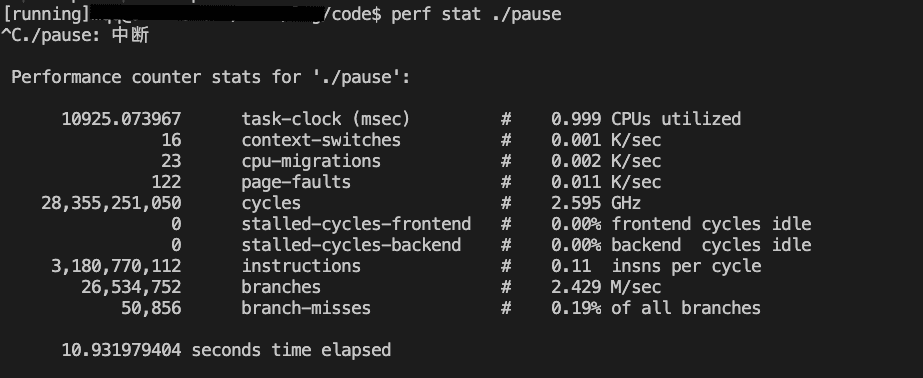
perf stat ./pause
现象
IPC只跑到了0.11
测试nop指令跑两份各自绑定到同一物理核
如何判断HT?通过查看/proc/cpuinfo信息, 如果physical id和core id都一样的话,说明这两个core实际是一个物理core,其中一个是HT
执行测试
taskset -c 0 perf stat ./nop
taskset -c 24 perf stat ./nop
现象
绑定在0号CPU上的IPC为2.42,绑定到24号CPU上的IPC为1.48,这两个CPU同属于一个物理核
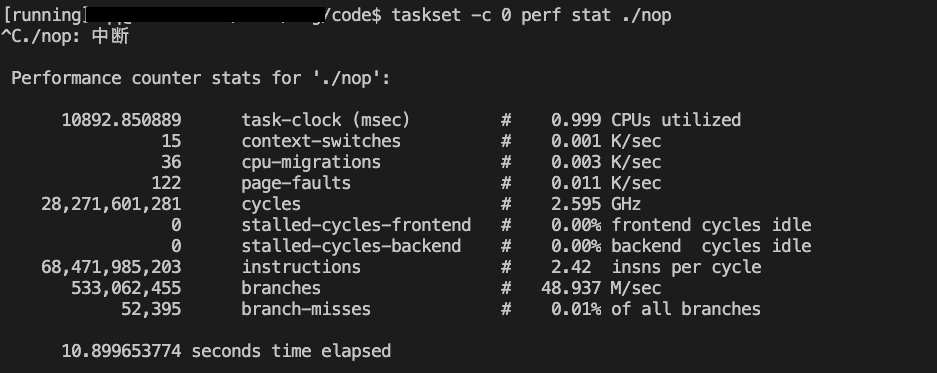
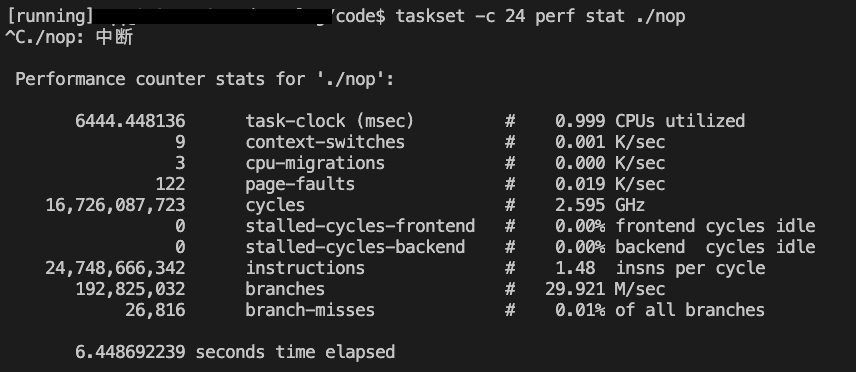
第一次测试时两个程序都运行在同一物理核上,IPC减半了
(2.42+1.48)/(3.79*2)=0.51
执行测试2(换了另一组同物理核)
taskset -c 1 perf stat ./nop
taskset -c 25 perf stat ./nop
现象
绑定在1号CPU上的IPC为1.94,绑定到25号CPU上的IPC为1.48,使用效率不到一半了
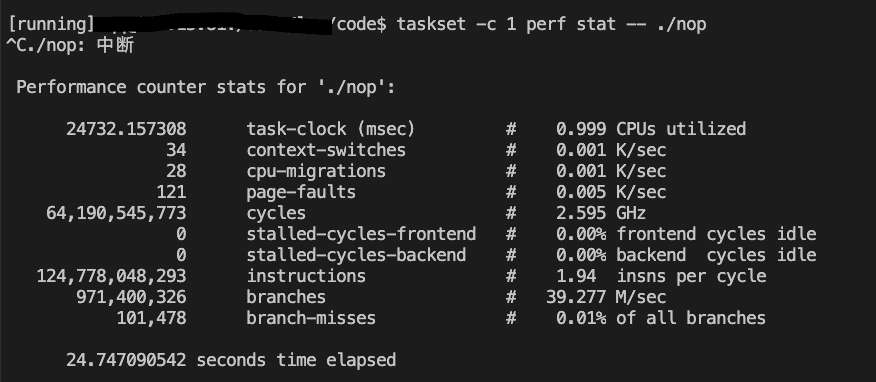
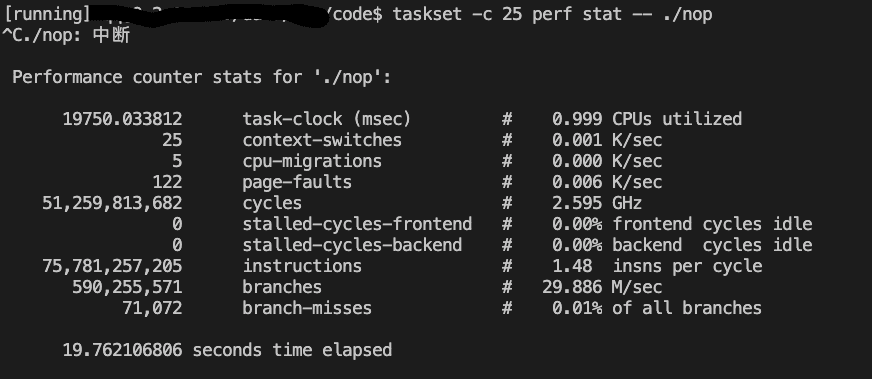
测试pause指令跑两份各自绑定到同一物理核
执行测试
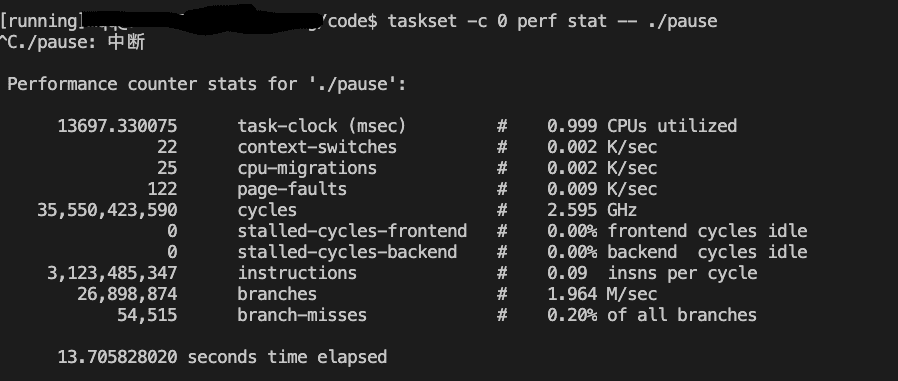
taskset -c 0 perf stat ./pause
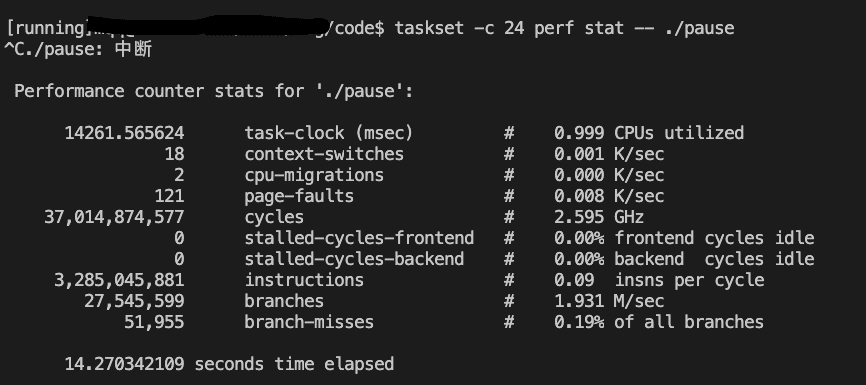
taskset -c 24 perf stat ./pause
现象
绑定在0号CPU上的IPC为0.09,绑定到24号CPU上的IPC为0.09
待解答问题
为什么死循环里要写这么多 pause? 写一次行不行?
我尝试了改代码只写一次pause,查看IPC也没什么变化,我理解是写一次的话流水线不饱和,但是不是有死循环呢吗?
有什么方式可以查看当前CPU的流水线长度吗?
待补充
总结
- 学习了perf命令
- 学习了taskset命令
- 学习了IPC对性能的影响
- 学习了超线程相关信息
- 上面学习到的都是需要后续深入研究的
番外
云机器动态开超线程
在网上搜索了linux动态开启HT的内容,找到一个脚本,在购买的云主机上尝试了一下不生效
尝试使用MAC测试
尝试了一下在MAC上是不是可以做这个实验,目前的结论是perf工具mac上可以使用gerftools,但是绑定指定核的命令 taskset 没有找到对应的工具,mac上好像不支持
虚拟上是不支持IPC结果显示的
直接上图